Individual Person Data (IPD) Meta-Analysis with Beta Regression in a Repeated-Measures Cross-Over Design
Individual Participant Data
Repeated Measures
Meta-Analysis
I worked on a meta-analysis along with my good friend Tylor J. Harlow on the effect of acoustic stimulations during slow-wave on memory retention. Since we have some individual participant data, I thought it would be fun to conduct an Individual Person Data (IPD) meta-analysis on it. Let me know if you have suggestions to improve this post.
Author
Matthew B. Jané
Published
October 31, 2024
Description of the Meta-analysis
Study design
The studies in this meta-analysis are investigating if auditory stimuli during slow-wave sleep can enhance overnight memory retention (this is based on theoretical reasons we don’t need to get into). In each study the participants undergo two sleep sessions reflecting two conditions. In one of the sessions, auditory stimuli (i.e., pink noise bursts) were presented while the subject’s were in deep slow-wave sleep (“stim” condition). In the other session there was no auditory stimuli (“sham” condition). These sleep sessions were separated by a week (or two) and were counter-balanced such that the ordering of conditions were randomized. Before subject’s go to sleep, subjects were given word-pairs that they are required to memorize. Prior to falling asleep they are assessed on how many word-pairs they can accurately remember (they are given one word and they are told to recall the other word). After the subjects wake up, they are assessed on the same task and the number of word-pairs they can remember correctly. So ultimately we have a repeated-measures (pre-post) cross-over (treatment-control) design.
We can load in the necessary packages Kay (2024) and get the data from my github repository.
We can see that each subject has four values: pre-stim, post-stim, pre-sham, and post-sham. The values denote the number of words recalled correctly and the total words column is the total number of word-pairs the subject was tasked to memorize. In total, there are 7 studies and 110 subjects.
Outcome of interest
Across studies the total number of word-pairs in the recall task varied (range: 80-120) and, consequently, so does the number of word-pairs correctly recalled. This produced different number of correctly recalled words. For this reason, we will choose to use probability of recalling a word-pair accurately.
Assume \(Y_{ij} \in \{0,1\}\) is a Bernoulli random variable that denotes whether a word-pair has been correctly recalled (1) or not (0) for assessment \(i\) and trial \(j\). Let each session \(i\) have it’s own probability distribution for \(Y\) such that \(Y_{ij} \sim \mathrm{Ber}(\pi_i)\) where the parameter \(\pi_i\) is the true probability of correctly recalling a word-pair for session \(i\) such that, \(\pi_i = \Pr_i(Y_{ij}=1)\). Our data set will contain observed proportions \(p_i = \frac{N_{\text{correct},i}}{N_{\text{total word-pairs},i}}\) which are estimates of \(\pi_i\). Therefore the outcome of interest is a probability-valued random variable \(\pi_i\) which is measured by the observed proportion \(p_i\).
Time and condition variables
We have two other Bernoulli random variables that represents time \(T_i\) (pre=0, post=1) and condition \(C_i\) (sham=0, stim=1). Of course, condition and time do not vary by trial so the subscript \(j\) is removed. We can condition the probability of correctly recalling a word (\(\pi_i\)) on values of \(T_i\) and \(C_i\) so that we have four possible experimental states,
Every participant has an observed proportion for all four experimental states: \(p^{(0)}_{\mathrm{pre},i}\), \(p^{(0)}_{\mathrm{post},i}\), \(p^{(1)}_{\mathrm{pre},i}\), and \(p^{(1)}_{\mathrm{post},i}\). What we want to do is make the data set long where condition is a dummy variable, this will set up our data such that we can fit an ANCOVA model in the next section.
dat <- df %>%# relabel the column headersrename(pre.sham = preSham, pre.stim = preStim, post.sham = postSham, post.stim = postStim) %>%# add row for person idmutate(person =1:nrow(df), .after = study) %>%# make data set long so that there is one column of scorespivot_longer(cols =c(pre.sham, post.sham, pre.stim, post.stim),names_to ="session",values_to ="num_correct") %>%# separate the session column into random variables time T and condition Cseparate(col = session, into =c("time", "condition")) %>%# recode variables as factors with levels 0 and 1pivot_wider(names_from = time,values_from =c(num_correct,total_words),id_cols =c(person,condition,study)) %>%# clean up variable values and calculate proportions mutate(condition =factor(condition, levels =c("sham","stim"), labels =c(0,1)),study =factor(study, levels =rev(c("N2013","N2015.1","N2015.2","W2016","H2019.1","H2019.2","S2020")),labels =rev(c("Ngo (2013)","Ngo (2015a)","Ngo (2015b)","Weigenand (2016)","Henin (2019)","Henin (2019)","Schneider (2020)"))),p_pre = num_correct_pre / (total_words_pre+(.005*total_words_pre)),p_post = num_correct_post / (total_words_post+(.005*total_words_post))) %>%# clean up columnsselect(study, person, condition, p_pre, p_post)# display cleaned data sethead(dat,8)
Now we have columns for the proportions at pre-test and post-test for each condition. Notice that each person has two rows pertaining to the stim and sham condition.
Effect Size of Interest
We would like to the estimate the effect of auditory stimulation on memory retention, so therefore we would like to compare the post-sleep recall proportion correct between conditions. Our effect size of interest can be the defined as the average difference between post-sleep recall scores in the treatment and control group conditioned on a pre-sleep score of .50,
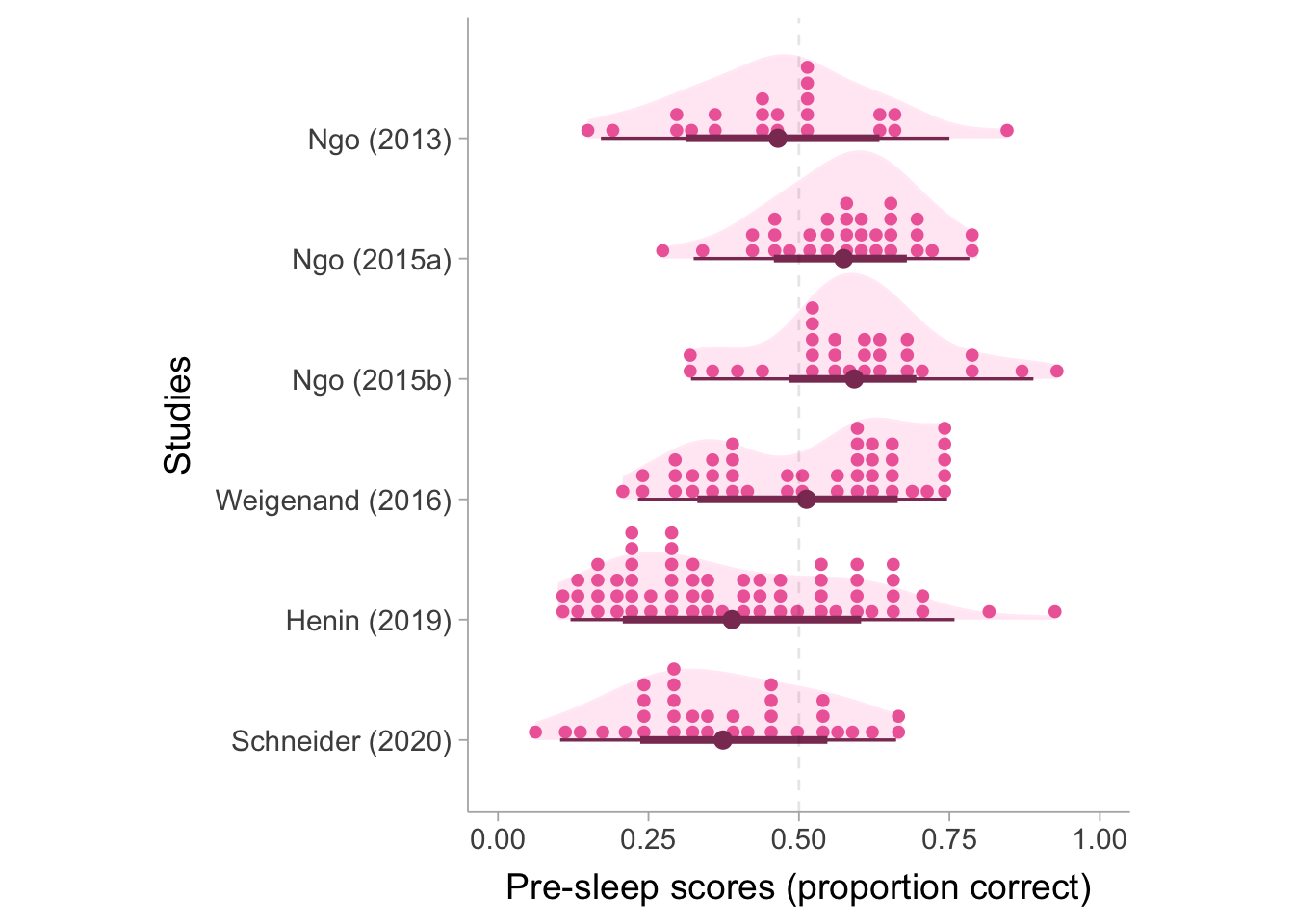
Since this effect size is essentially an average of risk differences, conditioning on a pre-sleep value of .50 is useful as is put succinctly by Karlson and Quillian (2023)“Risk differences are useful when base rates are in a middle range”. We will see that the IPD model will use the pre-sleep score as a covariate so conditioning on pre-sleep scores is straightforward. The grand average pre-sleep score is ~.47, which makes conditioning on .50 a bit easier to justify. We can visualize the pre-sleep scores for each study below, we can see that they are fairly evenly distributed around .50.
Distributions of pre-sleep scores by study. The dashed line denotes the 50:50 correct/incorrect value (\(p_\mathrm{pre} = .5\))
We can interpret the effect size as: on average, a typical person sees a \([\delta\times 100]\) percentage point increase in accurately recalling a word-pair in the stim condition relative to the sham condition. An effect size value of \(\delta < 0\) would indicate reduced recall in the stim group (i.e., stim was actually detrimental relative to sham), a value between \(\delta >0\) would indicate increased recall in the stim group (i.e., stim was beneficial relative to sham), and a value of \(\delta=1\) would be a null effect. Important to note that \(\delta\) is not standardized in this meta-analysis because scores are comparable across studies.
IPD Model (pre-sleep score as covariate)
With our data we can model the observed proportions as a beta distribution such that \(p_{\mathrm{post},i} \sim \mathrm{Beta}(\mu_i,\phi)\) where \(\mu_i\) is the conditional mean (i.e., \(\mu_i:=\mathbb{E}(p_{\mathrm{post},i}\, |\, p_{\mathrm{pre},i}, C_i )\)) and \(\phi\) is the concentration (\(\phi\) is inversely related to the variance and we can obtain the variance of \(p_i\) with \(\mu(1-\mu)/(\phi+1)\)). We can model the logit transformed \(\mu_i\) with an ANCOVA type model by using the pre-sleep scores as a predictor within a regression model.
To obtain person and study-level variability, we want to incorporate a random effect for study samples on each of the regression coefficients (there are 7 studies, denoted with subscript \(s = 1...7\)). We also allow the intercept to vary between individuals such that each person \(p\) has a random intercept (this is reasonable since there are individual differences in recall ability). Note that having condition vary by person (each person has 2 data points pertaining to treatment-control) would produce a model that is not identifiable. We will just use the default brms priors for all parameters.
mdl <-bf(p_post ~0+ Intercept + p_pre + condition + (1|person) + (1+p_pre+condition|study), family =Beta("logit"))prior <-default_prior(mdl, data = dat)fit <-brm(mdl,data = dat,cores =2, iter =2000,warmup =200,chains =3,prior = prior,file ="ipd_meta",file_refit ="on_change")
I recommend reading A. Solomon Kurz’s awesome blog post on Beta regression for causal inference, which inspired some of this model (if I made any mistakes that does not reflect on Solomon’s blog, that is just me being dense).
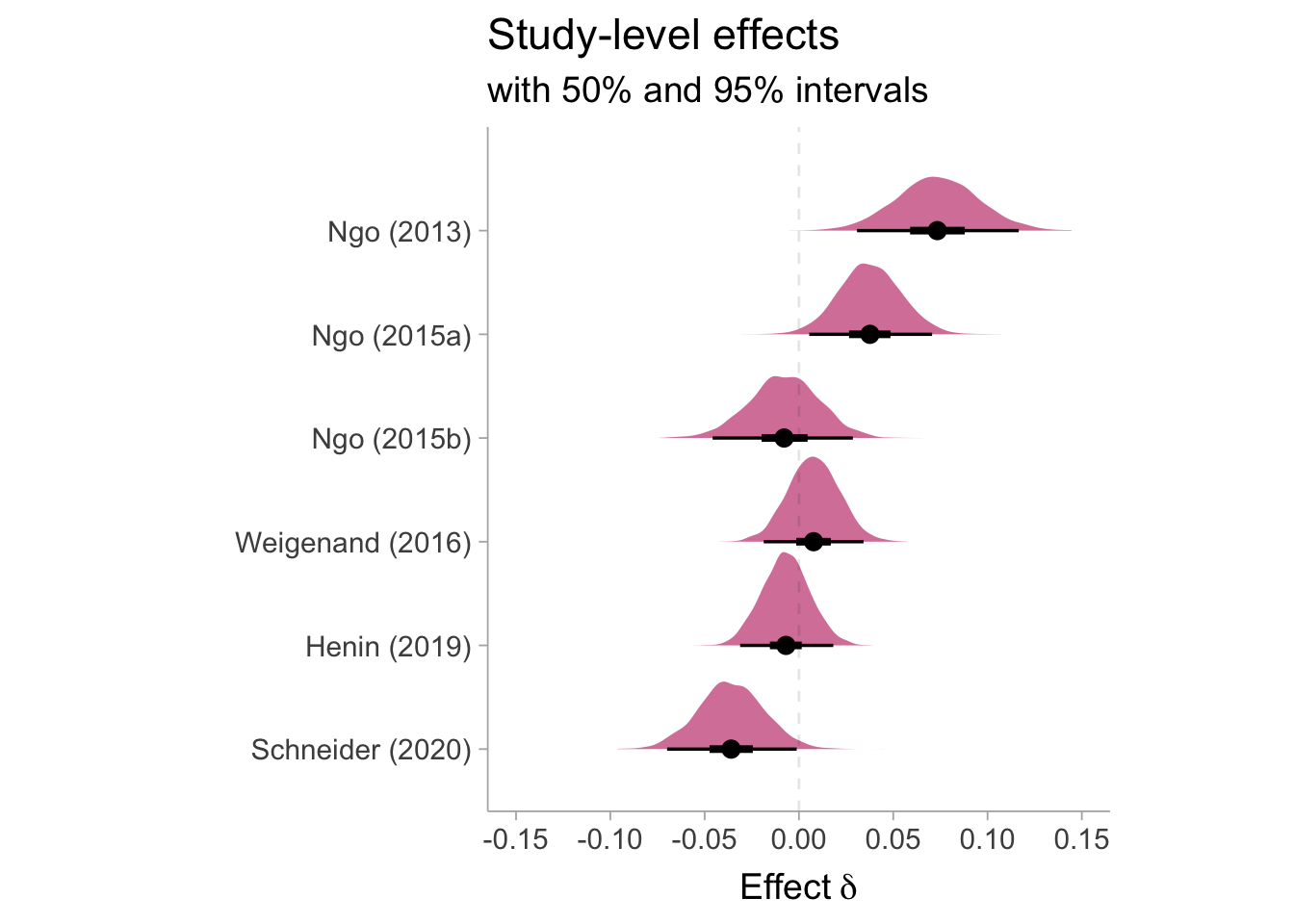
Study-level estimates of \(\delta\)
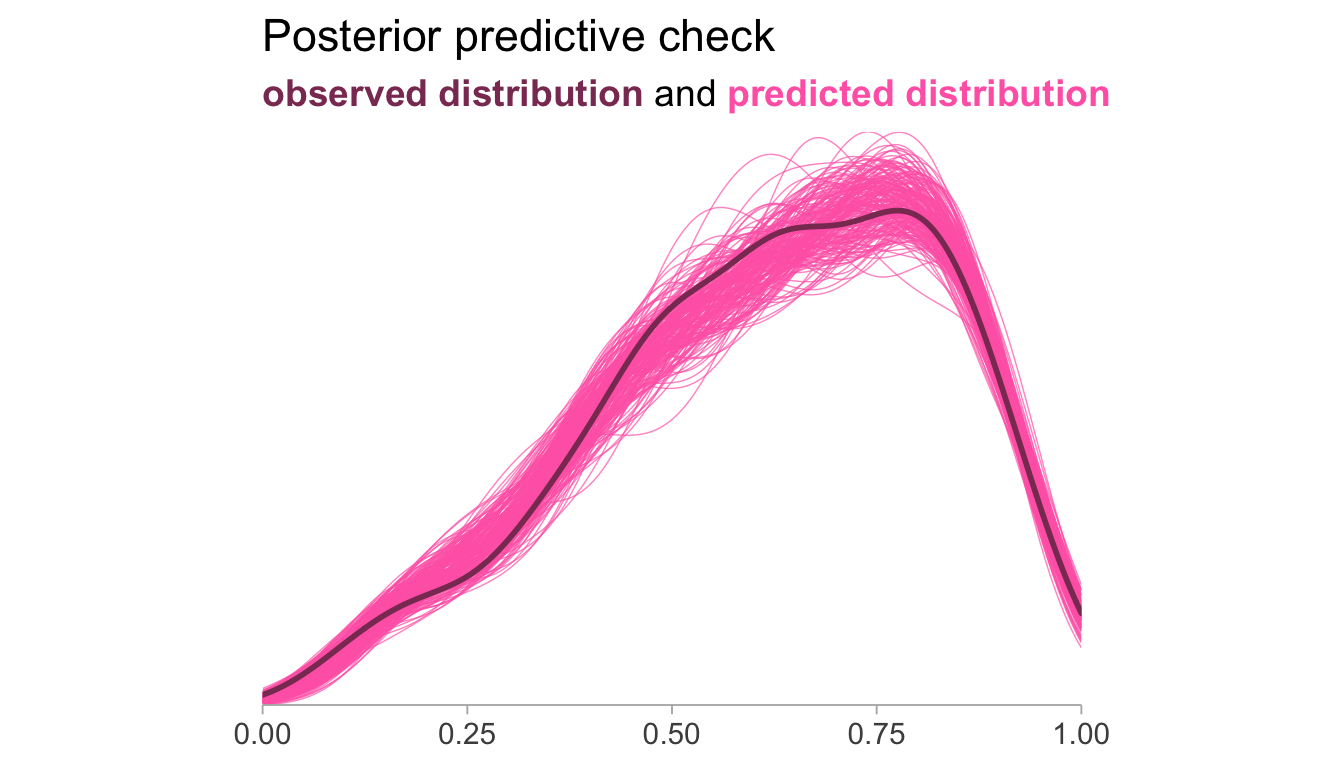
Let’s observe the posterior distribution of effects from each study in the meta-analysis. Visualizations created with the help of the awesome tidybayes and ggdist packages Kay (2023).
Study-level posterior estimates of the expected value of \(\delta\)
In our original paper we found a strong moderating effect of publication year on the effect size. Although we were only able to get a subset of the raw data sets, you can still see the shadow of that trend appears here.
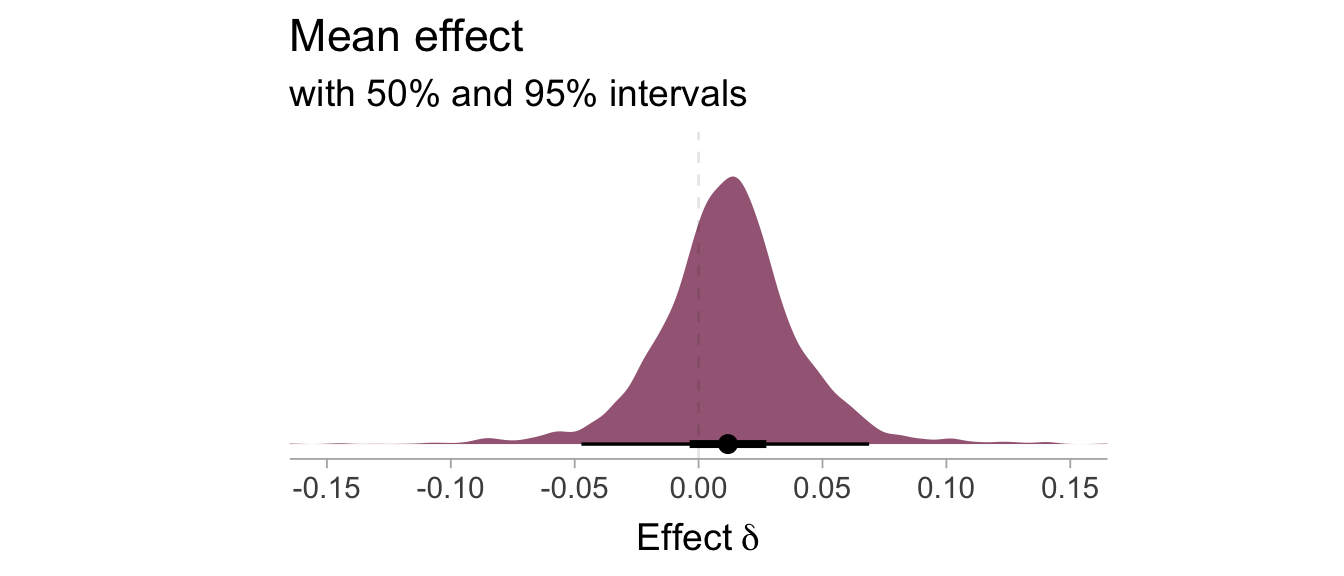
Mean Effect
Now we want to estimate the average effect across studies, the key here is to set the re_formula argument in the add_epred_draws to NA. The figure below denotes the distribution of plausible values for the average true effect.
As we can see there is little/no average effect of the stim condition 0.012 [-0.047, 0.069]. The estimate suggests there is about a 1% in recall probability difference from stim to sham.
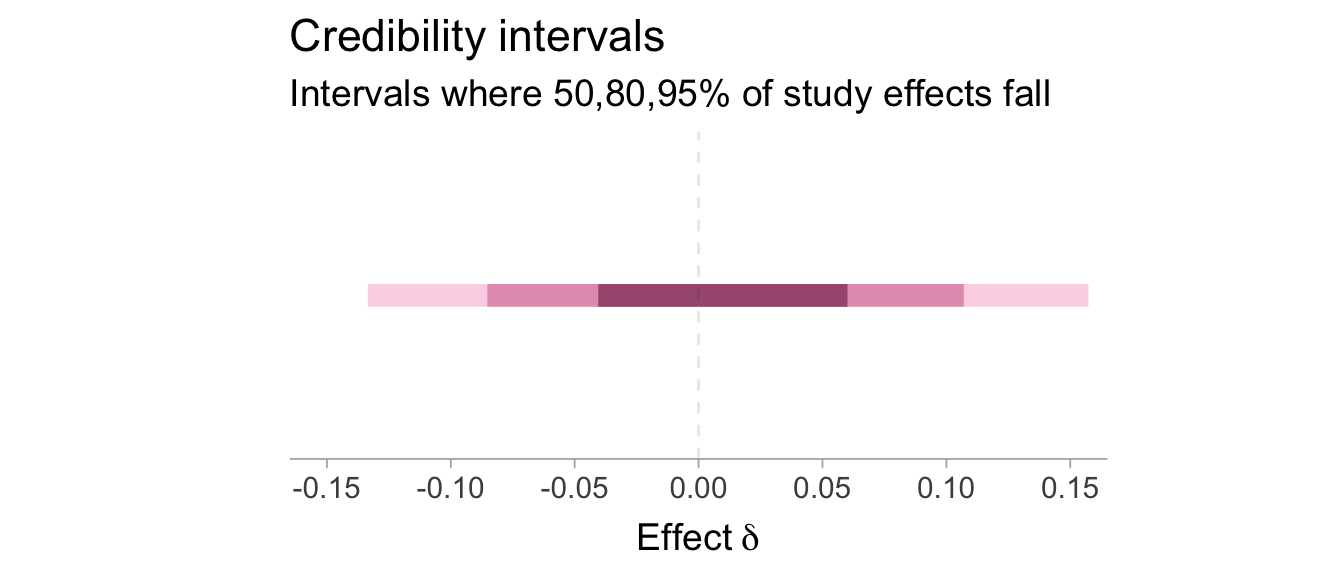
Let’s now obtain the credibility intervals which tells us what in what range of \(\delta\) do X% of study effects fall. The figure below will show 50, 80, and 95% credibility intervals. To do this in brms I am like 99% sure we just need to incorporate all the study-level random effects in the re_formula argument again. Therefore we would want to specify it as re_formula = ~(1+p_pre+condition|study).
Bürkner, Paul-Christian. 2021. “Bayesian Item Response Modeling in R with brms and Stan.”Journal of Statistical Software 100 (5): 1–54. https://doi.org/10.18637/jss.v100.i05.
Wickham, Hadley, Mara Averick, Jennifer Bryan, Winston Chang, Lucy D’Agostino McGowan, Romain François, Garrett Grolemund, et al. 2019. “Welcome to the tidyverse.”Journal of Open Source Software 4 (43): 1686. https://doi.org/10.21105/joss.01686.